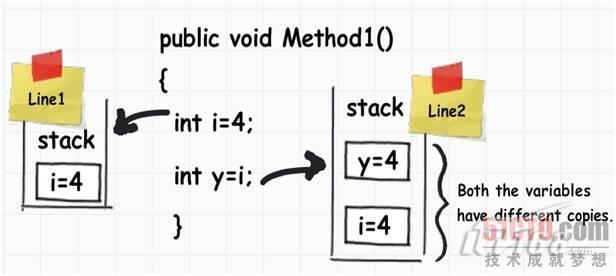
当你声明一个变量时内存中都发生了什么?* K! g6 E- E5 Z$ G( Z" t" r9 p y 当你在一 个.Net应用程序中声明一个变量时,首先要分配一些内存快到 RAM,它包括三样东西,{dy}个是变量名,第二个是变量的数据类型,{zh1}一个是变量的值。 ; [: M ~) x! Q5 g 这只是一个很简单的解释,根据变量的数据类型不同,有两种内存分配类型:堆栈内存和堆内存。3 U `1 c8 l2 t; {; h/ h $ c/ A- a" n+ h N: Q8 f. O* P  声明变量后的内存结构 $ ~2 e1 K3 u% B1 d! J$ ^! a5 s* o+ H 堆栈(stack)和堆(heap) 为了帮助理解堆 栈和堆,让我们了解下面的代码内部究竟发生了什么。 这个方法内部只有三行代码,下面我就逐行解释内部 发生了什么事情。) G) Z1 L; ?/ `6 k; k 8 j; G1 u/ g! S9 t0 s7 @ {dy}行:执行该行时,编译器分配一小块叫做堆栈的内存,堆栈负责保持跟踪应用程序运行需要的内存。 第二行: 现在执行移动到下一步,正如堆栈的名称所暗示的那样,这个内存分配时叠放在前一个内存分配顶部的,你可以将堆栈理解为一系列隔间或盒子的逐层堆积。 * }, T5 Q" U. a1 z0 l( f 内存分配和解除分配使用LIFO(Last in first out,后进先出)逻辑,换句话说就是内存是在内存的末尾(如堆栈的顶部)分配和解除分配的。 7 ]- a) F9 ]8 Q4 j& t$ X 第三行:在第三行我们创建了一个对象,执行该行时,它在堆栈上创建一个指针,真实的对象是存储一个不同类型的内存分配(叫做堆)中,堆不会跟踪运行的 内存,它只是对象的堆积,堆用于动态内存分配。3 S: v# k' |% l9 ]% h& ?# D- y 退出方法(有趣):执行完{zh1}一行 代码后就该退出这个方法了,当它传递结束控制时,它就会xx分配到堆栈上的所有内存变量,换句话说就是所有与int数据类型关联的变量按照LIFO方式从 堆栈中解除分配。 ) ] z( l. C6 t7 r0 e; b 但不会解除堆内存分配,这部分内存要通过GARBAGE COLLECTOR(垃圾回收器)解除分配。$ g. ]4 x7 o) U1 o8 W8 \5 y  很多人现在可能要问为什么要设置两种内存分配形式呢?难道就不能用一种内存分配形式完成内存分配吗? ; Z" r( T6 `1 W1 S 如果你仔细观察上图,你就会知道int变量是分配在堆栈上的,因为编译器已经知道它们可以存储多少数据(-2,147,483,648到 2,147,483,647),涉及到对象时,编译器不知道需要多少内部空间,因此在堆上分配相同大小的空间。; V6 n6 d/ V, I+ X4 v ! @, z' N' d' o8 S' U9 n) M3 X 换句话说就是,如果不知道数据大小或是动态变化的,就需要分配到堆上,如果数据大小是确定的,就分配到堆栈上。  值类型和引用类型' d2 X4 R2 g( ^" {- u' c! ~0 Y 值类型指的是在相同的位置同时容纳数据和内存的类型,而引用类型是借助一个指针指向内存位置。下面是一个简单的命名为i的整数数据类型,其值是由另一 个命名为j的整数数据类型赋予的,这两个内存值都是基于堆栈分配的。 当我们将一个int值赋给另一个int值 时,它创建一个xx不同的拷贝,换句话说就是,你修改其中一个值不会引起另一个值也发生变化,这种数据类型就叫做值类型。
当我们将一个对象赋值给另一个对象时,它 们指向相同的内存位置,如下图所示,当我们将obj赋值给obj1时,它们指向的内存位置是一样的。换句话说就是,如果我们修改了其中一个对象,另一个对 象也会受到影响,这种类型就叫做引用类型。
哪一个数据类型是值类型和引用类型呢?8 A" D6 t, x* D; Z* j 在.Net中,根据数据类 型不同,变量可能是基于堆栈分配的,也可能是基于堆分配的,String和Objects是引用类型,其它.Net数据类型是基于堆栈分配的,下图更详细 地进行了解释。, p; N5 y" {. R& l4 `
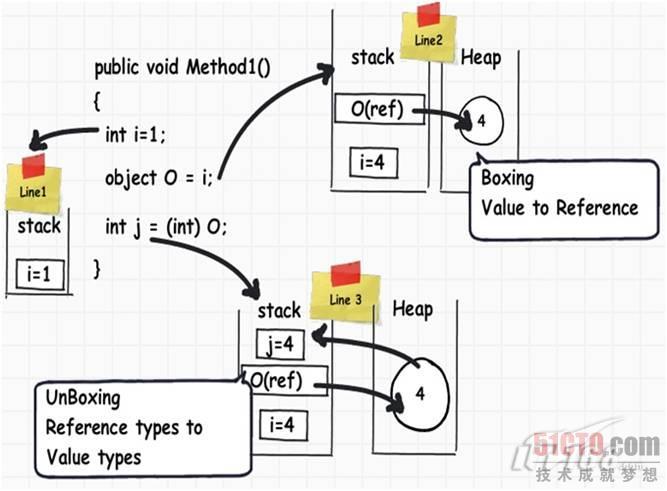
说了这么多, 在实际编程时怎么使用它们呢?{zd0}的问题是要弄清楚数据从堆栈移到堆的性能损失,反之亦然。 如下图所示,当我们将一个值类型移到引用 类型时,数据也从堆栈移到堆中,当我们将引用类型移到值类型时,数据就从堆移到堆栈中。数据从堆栈移到堆,或是从堆移到堆栈,都会产生较大的性能损失。数 据从值类型移到引用类型的过程叫做装箱,从引用类型移到值类型叫做拆箱。
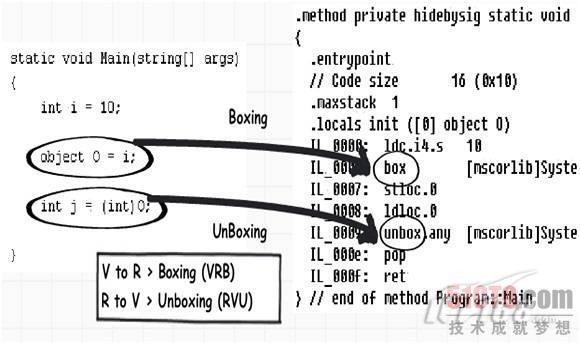
如果你编 译上面的代码,在相同的ILDASM中,你会看到在IL中的代码是如何装箱和拆箱的,如下图所示。
装箱和拆箱的性能 影响; g' k H+ S; v6 `, T; U& b4 p. M1 M 为了查看性能的影响,我们将下面两个函数运行了1000次,如下图所示,左边的函数有装箱拆箱操作,右边的函数没有,我们使用了一个秒表对象监控所花 的时间。$ s( N- H7 [; Y6 g0 T; M
从上图我们看到,有 装修拆箱需要花3542毫秒,无装修拆箱只需2477毫秒,因此对性能的影响还是蛮大的。7 c v, K0 q3 _* _ |

 1 R: ^, {1 O* c; A6 g
1 R: ^, {1 O* c; A6 g / x, ]1 d, ?2 K1 D5 ~& {1 z
/ x, ]1 d, ?2 K1 D5 ~& {1 z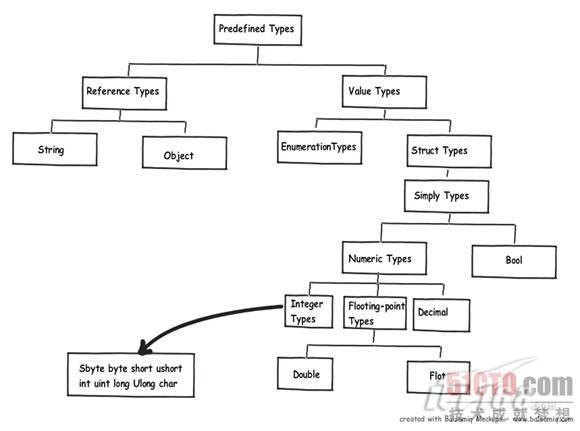
 # e( h) f- l& J* W; h
# e( h) f- l& J* W; h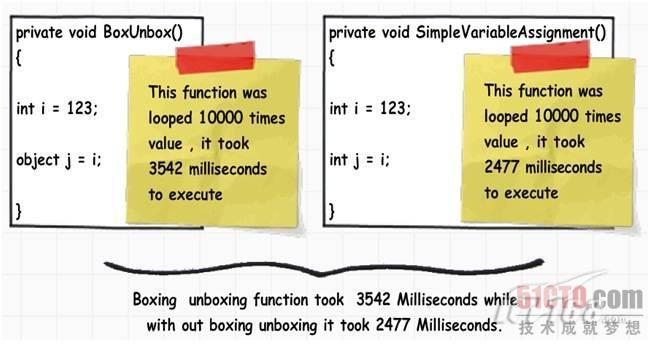 6 q+ [8 a E/ Z) B/ O" k2 Y
6 q+ [8 a E/ Z) B/ O" k2 Y
郑重声明:资讯 【.net中几个较难的概念_乔木和小乔_百度空间】由 发布,版权归原作者及其所在单位,其原创性以及文中陈述文字和内容未经(企业库qiyeku.com)证实,请读者仅作参考,并请自行核实相关内容。若本文有侵犯到您的版权, 请你提供相关证明及申请并与我们联系(qiyeku # qq.com)或【在线投诉】,我们审核后将会尽快处理。
—— 相关资讯 ——


